With Change analysis, you can compare any two data points in a visualization for change and identify key change drivers from the underlying attribute columns.
Change analysis
Change analysis compares data points of simple or complex measures using these aggregates:
• Sum
• Count
• Sum over sum, which generates ‘what-if’ percentage insights
• Average, which generates ‘what-if’ percentage insights
• Other functions which use a ‘versus’ analysis to show the absolute change grouped by different drill attributes
Contextual change analysis
Trendata supports contextual change analysis for area, line, column, bar, line-column, donut, and KPI charts. Contextual change analysis works by looking at the difference between the value of a measure across two points, then slicing both the points along another attribute. Then the changes are analyzed to see if the attribute can be used to explain the differences in the two points.
To perform this analysis, follow these steps:
1. On an area, line, column, bar, line-column, pie, or KPI chart, hold down the command key (macOS) or control key (Linux or Windows).
2. Select the two columns or data points you plan to compare.
Note that if you are analyzing a KPI chart, you must either click the percent change label or select two points from the sparkline visualization. You cannot run change analysis on a KPI chart with no sparkline visualization.
3. Right-click to see the dropdown menu, and select Run change analysis.
4. The Change analysis window modal appears with the results of your analysis. By default, Change analysis picks the top 5 most relevant columns, based on what it learned from your past activity.
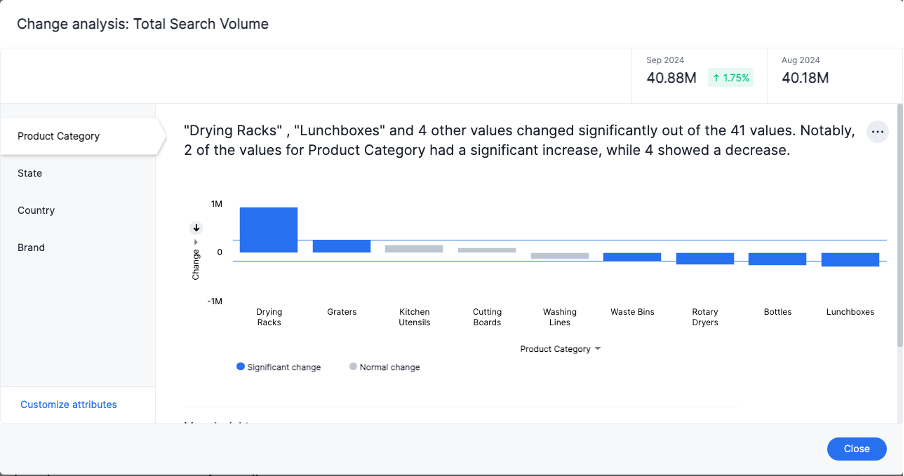
To select other columns to analyze, click Customize attributes in the lower left corner of the window and select the desired column from the window that appears.
Each colored section of a Change analysis insight represents a statistically significant outlier among the values of your chosen columns. For more information on how statistically significant outliers are calculated, see How contextual change analysis is calculated, further down this academy.
5. You can now examine each visualization of the analysis for details of comparison.
In some instances, Trendata may point out that certain attribute values account for more than 100% of the total change. This is generally for cases where attribute values contribute to a trend that is opposite to the total change (positive change when the overall trend is negative, for example). You may see cases, for example, where two attribute values account for a 300% increase in search volume, while the remaining attribute values indicated account for 200% of the total decrease.
6. You can add the specific visualization to an existing Liveboard, or create a new Liveboard and add it there.
7. You can run another round of Change analysis, download the data as a CSV file, edit this visualization, or make a copy of the visualization.
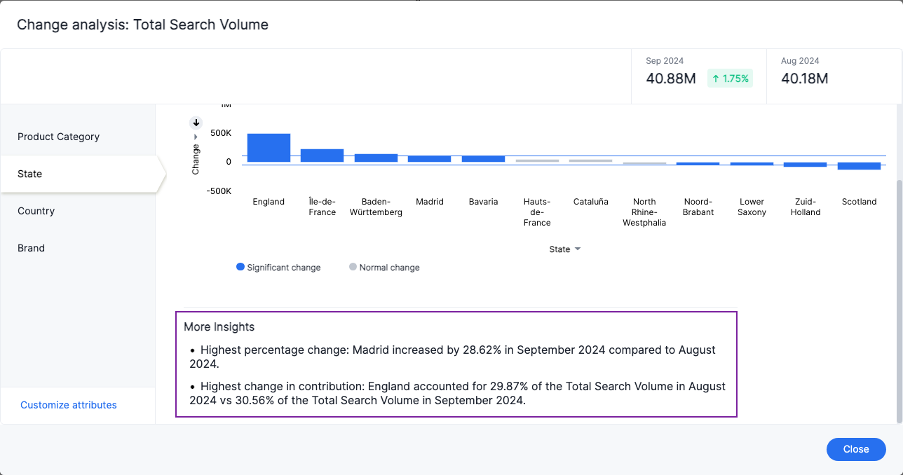
When you run change analysis, Trendata detects additional insights and displays them below the change analysis visualizations. These insights display values that underwent the highest percentage change between the data points defined in your analysis, and values whose share of the total changed the most. Note that insights do not appear for measures of type unique counts and ratios.
Iterative change analysis
You can now drill down on the results of change analysis to learn more about change drivers in your data.
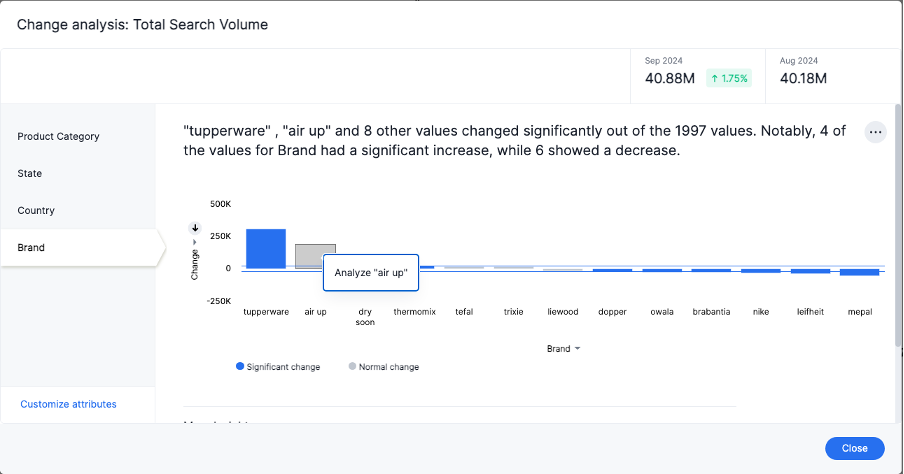
To run iterative change analysis, follow these steps:
1. Select two points on a chart and right-click to select Run change analysis.
2. Right-click on an attribute value in the resulting change analysis and select Analyze <attribute_value>. For example, if you want to deep-dive to understand what’s driving change in “California” in “State” attribute, right click on “California” and click “Analyze California”.
3. ThoughtSpot adds the specified attribute value as a filter and re-calculates change analysis for the original comparison points.
Natural language narratives
Trendata generates insight narratives in natural language to summarize the data analyzed in change analysis. The narratives are generated by LLM, and appear above the charts created by change analysis.
How contextual change analysis is calculated
In order to process different aggregations in the data, contextual change analysis is broken into three categories.
Type 1 - Simply decomposable
A simply decomposable measure can be expressed as a disjoint union of finite measures. For example, measures having aggregation SUM or COUNT. SUM(x + y) = SUM(x) + SUM(y).
Type 2 - Ratio of simply decomposable
Measures in this type are ratios of measures from type 1. For example, measures of the form AVERAGE or SUM/SUM.
Type 3 - Unknowns
Measures that are neither in type 1 nor in type 2 fall under this type. For example, UNIQUE COUNT, SUM * SUM.
Type 1 algorithm
We compare measurements at two different times for each attribute. Then, we calculate the upper and lower thresholds based on the most significant absolute changes between these two timestamps. Any change values lying outside the range of threshold values are marked as outliers.
We determine the upper and lower thresholds by looking at the top ten absolute changes. If the combined contribution of a measure at the first or second timestamp exceeds 50%, we stop iterating. The largest negative change becomes the lower threshold, while the smallest positive change becomes the upper threshold.
Example 1
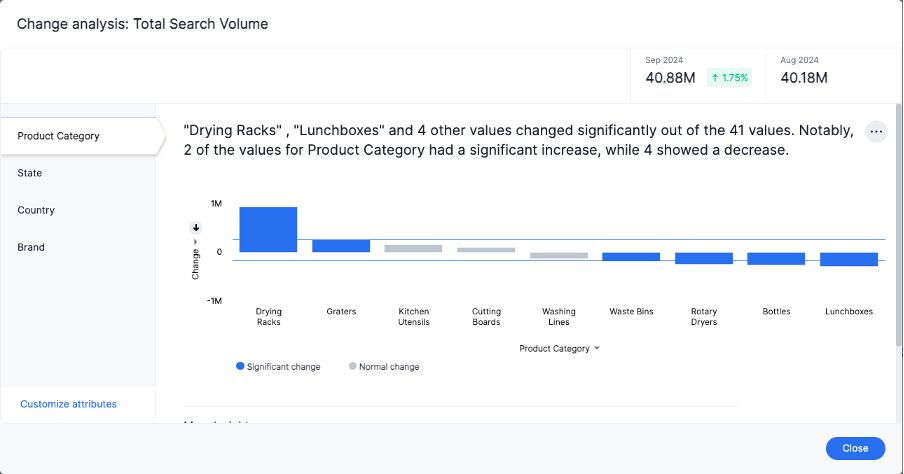
In the example above, based on the absolute change values, the upper threshold is calculated as 254K, and the lower threshold value is calculated as -181.8K. Attribute values lying on or outside the threshold values are marked as outliers.
Type 2 algorithm
We start by comparing measurements at two different times for each attribute. Next, we treat the changes as a normal distribution and calculate the values of upper and lower thresholds using the Z-score calculation. Any change values lying outside the range of threshold values are marked as outliers.
A Z-score represents the number of standard deviations from the mean a data point is. Z-scores are a way to compare results from a test to a “normal” population. The basic Z-score formula for a sample is: z = (x – μ) / σ where σ is the standard deviation, μ is the mean, x is the data value. Upper threshold is assigned as μ + N * σ and lower threshold is assigned as μ – N * σ. So any value with a Z-score less than or greater than N is an anomaly.
The minimum value of N is 2.0, which covers 95.45% of points in a normal distribution. The maximum is 5.0, which covers 99.99994% of points in a normal distribution. The value of N is decided according to the table provided below:
Attribute Cardinality | Value of N |
<= 100 | 2.0 |
500 | 2.69 |
2000 | 3.301 |
10000 | 4.0 |
50000 | 4.69 |
>= 100000 | 5.0 |
Limitations
• Change analysis is not yet supported on measures that are created using group_* formulas.
• Change analysis is not supported on queries based on the “growth of” keyword.
• Change analysis is not supported on queries based on the “versus” keyword.